How Data Scientists Can Optimize AI Reward Strategies for Complex Environments: 3 Powerful Techniques
What if you could develop an AI that not only plays a game as complex as AlphaGo but also navigates clinical trials or optimizes urban planning? These are just a few examples of how optimizing AI reward strategies can revolutionize various fields.
As a life coach, I’ve helped many professionals navigate these challenges. I’ve seen firsthand how daunting it can be to optimize AI reward strategies in complex environments, especially when dealing with reinforcement learning and multi-agent systems.
In this post, you’ll discover proven strategies to stand out and accelerate your career growth by mastering reinforcement learning applications and optimizing AI reward strategies. We’ll explore topics like reward shaping, the exploration-exploitation tradeoff, and how neural networks and deep learning play a role in these processes.
Let’s dive in and explore how optimizing AI reward strategies can transform machine learning algorithms and push the boundaries of what’s possible with artificial intelligence.

The Challenge of Optimizing AI Reward Strategies
When diving into complex environments like clinical trials, game playing, and urban planning, the intricacies can be overwhelming. Many clients initially struggle with understanding multi-objective optimization and designing effective reward strategies for machine learning algorithms.
This often results in inefficient AI systems that fail to meet their full potential, particularly in reinforcement learning and multi-agent systems.
In my experience, consultants and decision-makers often face significant challenges. The complexity of these environments makes it hard to pinpoint the optimal reward strategies for neural networks and deep learning models.
It’s a daunting task that requires a nuanced approach and a deep understanding of the specific objectives, including exploration-exploitation tradeoffs in Markov decision processes.
Moreover, the pain of getting it wrong can be substantial. Poorly designed reward functions can lead to suboptimal AI performance, wasting time and resources. Effective reward shaping is crucial for success.
It’s crucial to tackle these challenges head-on with the right strategies and tools, such as Bayesian optimization and curriculum learning, when optimizing AI reward strategies.
Roadmap to Optimizing AI Reward Strategies
Overcoming this challenge requires a few key steps. Here are the main areas to focus on to make progress in optimizing AI reward strategies:
- Design Multi-Objective Reward Functions: Conduct workshops, use simulation tools, and collaborate with stakeholders to develop effective reward strategies for reinforcement learning and multi-agent systems.
- Implement Actor-Critic RL Architecture: Develop prototypes using machine learning algorithms, mentor junior data scientists, and evaluate the model’s performance in real environments, considering the exploration-exploitation tradeoff.
- Use Gradient-Based Policy Optimization Methods: Attend training sessions on deep learning and neural networks, apply policy gradient methods, and conduct peer reviews for robust optimization of AI reward strategies.
Let’s dive into optimizing AI reward strategies!
1: Design multi-objective reward functions
Designing multi-objective reward functions is crucial for optimizing AI reward strategies in complex settings like urban planning and clinical trials. This process often involves machine learning algorithms and reinforcement learning techniques.
Actionable Steps:
- Organize workshops with domain experts to identify and prioritize the specific objectives of your AI system, focusing on reward shaping and multi-agent systems.
- Implement simulation scenarios to iteratively test and adjust reward functions, ensuring they align with real-world outcomes and address the exploration-exploitation tradeoff.
- Set up regular meetings with stakeholders to gather feedback and make necessary adjustments to the reward functions, considering neural networks and deep learning approaches.
Key benefits of well-designed reward functions:
- Improved alignment with real-world goals
- Enhanced system performance in complex environments
- Greater stakeholder satisfaction and buy-in
Explanation: These steps matter because they ensure that the reward strategies are well-aligned with the specific goals of your application, often utilizing Markov decision processes.
Engaging with domain experts and stakeholders helps tailor the reward functions to real-world needs, while simulations allow for continuous refinement. This process may involve Bayesian optimization and curriculum learning techniques.
According to a recent study, using deep reinforcement learning for urban land use optimization significantly reduces travel-related carbon emissions, showcasing the importance of well-designed reward functions in optimizing AI reward strategies.
Take these steps to ensure your AI systems are robust and aligned with real-world objectives, setting the stage for successful implementation of optimized AI reward strategies.

2: Implement Actor-Critic RL architecture
Implementing an Actor-Critic RL architecture is crucial for optimizing AI reward strategies and enhancing AI systems’ decision-making in complex environments.
Actionable Steps:
- Develop a prototype using open-source libraries like Gymnasium or Stable Baselines. Start by creating a simple reinforcement learning model to experiment with the Actor-Critic framework and explore the exploration-exploitation tradeoff.
- Mentor junior data scientists on the nuances of Actor-Critic methods and machine learning algorithms. Host mentorship sessions to guide your team through the implementation process, covering topics like neural networks and Markov decision processes.
- Evaluate the model’s performance in real environments. Deploy the model in a controlled setting and measure its performance against key metrics, focusing on optimizing AI reward strategies through reward shaping and curriculum learning.
Explanation: These steps are vital because they ensure practical application and knowledge transfer within your team. Building prototypes with tools like Gymnasium provides hands-on experience with multi-agent systems, while mentoring sessions enhance team skills in deep learning and Bayesian optimization.
Regular evaluation ensures your model’s alignment with real-world goals. According to Noble Desktop, integrating RL with deep learning techniques can handle complex state spaces effectively.
Taking these steps will equip your team to implement and refine Actor-Critic RL architectures, setting the stage for more robust AI systems and optimizing AI reward strategies.
![]()
3: Use gradient-based policy optimization methods
Using gradient-based policy optimization methods is essential for optimizing AI reward strategies and achieving optimal performance in complex environments.
Actionable Steps:
- Enroll in advanced courses on gradient-based policy optimization to enhance your skills in reinforcement learning. Consider webinars or specialized training sessions for a deeper understanding of machine learning algorithms.
- Implement policy gradient algorithms in your RL model. Focus on tuning the parameters based on the gradient of expected rewards, considering the exploration-exploitation tradeoff.
- Arrange peer review sessions to critique and improve the optimization methods applied in your RL models. This ensures robustness and reliability in multi-agent systems.
Advantages of gradient-based policy optimization:
- Direct optimization of policy parameters
- Effective in high-dimensional action spaces
- Improved sample efficiency in learning
Explanation: These steps matter because they provide a structured approach to optimizing your AI models and reward strategies.
Advanced training equips you with the necessary skills in deep learning and neural networks, while implementing and reviewing policy gradient methods ensures practical application and continuous improvement in Markov decision processes.
According to Medium, policy gradient methods directly optimize the policy by adjusting the parameters of the policy network using the gradient of expected rewards.
Taking these steps will help you refine your AI systems, making them more effective and efficient in complex environments through techniques like reward shaping and curriculum learning.

Partner with Alleo on Your AI Journey
We’ve explored the challenges of optimizing AI reward strategies. Did you know you can work directly with Alleo to make this journey easier and faster for your reinforcement learning projects?
Set up your account and create a personalized plan. Alleo’s AI coach provides affordable, tailored coaching support for optimizing AI reward strategies and machine learning algorithms.
Full coaching sessions mimic human coaches and include a free 14-day trial, requiring no credit card. Our approach covers various aspects of AI, including neural networks and deep learning.
The coach will follow up on your progress, handle changes in your multi-agent systems, and keep you accountable with text and push notifications, helping you navigate the exploration-exploitation tradeoff.
Ready to get started for free and improve your AI reward strategies? Let me show you how!
Step 1: Log In or Create Your Account
To begin your AI optimization journey with Alleo, Log in to your account or create a new one to access personalized coaching and support for mastering reinforcement learning applications.

Step 2: Choose Your AI Optimization Goal
Select “Setting and achieving personal or professional goals” to focus your AI coach on optimizing your reward strategies for complex environments like clinical trials or urban planning, aligning your learning journey with the challenges discussed in reinforcement learning applications.

Step 3: Select “Career” as Your Focus Area
Choose “Career” as your focus area to align your AI optimization goals with professional growth, enabling you to tackle complex reinforcement learning challenges and advance in fields like clinical trials or urban planning.

Step 4: Starting a coaching session
Begin your AI optimization journey with an intake session, where you’ll discuss your goals and challenges in implementing reinforcement learning strategies, allowing the AI coach to create a personalized plan tailored to your specific needs in complex environments like clinical trials or urban planning.

Step 5: Viewing and Managing Goals After the Session
After your AI coaching session on optimizing reward strategies, you can easily view and manage your goals directly from the app’s home page, allowing you to track your progress in implementing advanced reinforcement learning techniques.
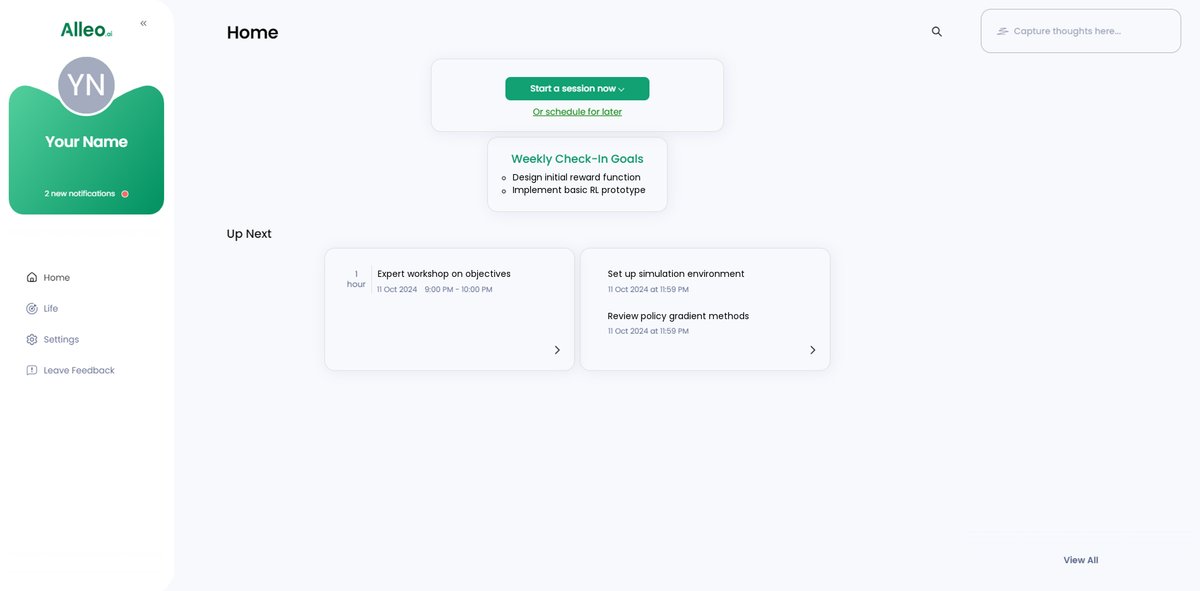
Step 6: Adding events to your calendar or app
Track your AI optimization progress by adding key milestones and tasks to the Alleo app’s calendar and task features, ensuring you stay on schedule with your reinforcement learning implementations and reward strategy refinements.
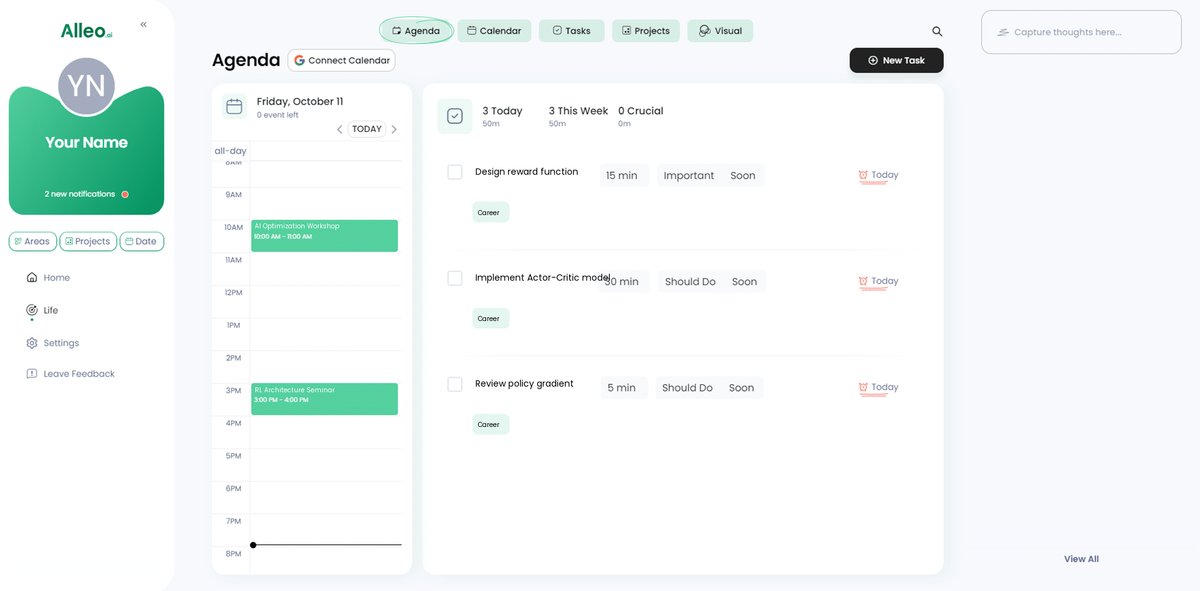
Wrapping Up Your AI Optimization Journey
We’ve covered a lot, right? From designing multi-objective reward functions to implementing Actor-Critic architectures and using gradient-based policy optimization methods for optimizing AI reward strategies.
It’s essential to understand these strategies to navigate complex environments effectively, especially when dealing with reinforcement learning and multi-agent systems.
Remember, the key is to align your AI systems with real-world objectives and continuously refine your methods, including reward shaping and exploration-exploitation tradeoff techniques.
I know it can seem overwhelming, but you’re not alone in this journey of optimizing AI reward strategies.
Let Alleo be your guide. Our AI coach offers personalized support tailored to your needs, whether you’re working with neural networks, deep learning, or Markov decision processes.
Take the first step and try Alleo for free. Empower your AI systems and achieve your goals with confidence in machine learning algorithms and Bayesian optimization.